
| short Register |
long Register |
Adressregister |
|
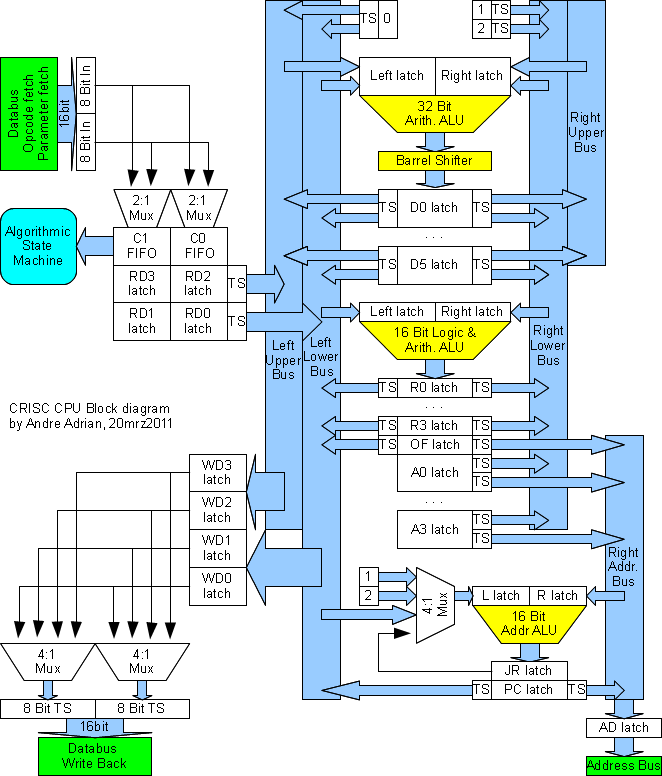
| CRISC CPU |
R0 bis R3 |
D0 bis D5 |
A0 bis A3 |
| 68000 |
D0 bis D7 |
A0 bis A7 |
|
| 80386 |
EAX, EBX, ECX, EDX | ESP, EBP, ESI, EDI |
| Name |
Klasse |
C |
Funktion |
| NOP |
Kontrolle |
Erhöhe Program Counter um 1 |
|
| RET |
Kontrolle |
return; |
Rückkehr vom Unterprogramm |
| NOT |
Logik |
R0 = ~R0 |
Bits invertieren,
Einserkomplement bilden |
| NEG |
Arithmetrik | D0 = -D0 |
Vorzeichen wechseln,
Zweierkomplement bilden |
| ASR |
Schiebe |
D0 >>= 1 oder D0 >>=
8 |
Arithmetrisch rechts schieben,
das Vorzeichen beim Schieben beibehalten |
| LSR |
Schiebe |
D0 >>= 1 oder D0 >>= 8 | Logisch rechts schieben, die
freiwerdene Stelle mit 0 füllen |
| SL |
Schiebe |
D0 <<= 1 oder D0 <<=
8 |
Links schieben, die freiwerdene Stelle mit 0 füllen |
| RR |
Schiebe |
Rechts rotieren mit Carry C
>> D0 >> C |
|
| RL |
Schiebe |
Links rotieren mit Carry C
<< D0 << C |
|
| AND |
Logik |
R0 &= R1 |
UND Verknüpfung |
| OR |
Logik |
R0 |= R1 N,Z = f(0 | R0) |
ODER Verknüpfung oder führe ODER Verknüpfung mit 0 aus um Flags zu setzen (entspricht TST) |
| XOR |
Logik |
R0 ^= R1 |
EXKLUSIV ODER Verknüpfung |
| ADD |
Arithmetrik |
R0 += R1 R0 += 1 |
Addiere Inhalt des zweiten
Registers zum Inhalt des ersten Registers oder addiere Konstante zum Inhalt des Registers (entspricht INC) |
| SUB |
Arithmetrik | R0 -= R1 R0 -= 1 |
Subtrahiere Inhalt des zweiten
Registers vom Inhalt des ersten Registers oder subtrahiere Konstante vom Inhalt des Registers (entspricht DEC) |
| CMP |
Arithmetrik |
N,C,V,Z = f(R0 - R1) |
Wie SUB, aber das Register wird
nicht verändert, nur die Flags werden gesetzt |
| JMP |
Kontrolle |
goto X; |
Springe unbedingt |
| Jcc |
Kontrolle |
if (), while(), for() |
Springe bedingt in
Abhängigkeit von cc |
| Scc |
Kontrolle |
R0 = f(N,C,V,Z) |
Lade Register mit -1 oder 0 in Abhängigkeit von cc |
| JSR |
Kontrolle |
func(); |
Unterprogrammaufruf |
| LD |
Transport |
Kopiere mit optionalen Sign
Extend von Memory nach Register oder kopiere von Register nach Memory |
| Adressierungsart |
C Beispiel |
Assembler |
Erklärung |
| Implied |
return; |
RET |
Rückkehr vom
Unterprogrammaufruf ausführen. |
| Immediate | r0 = 0xAFFE; | LDW R0,#$AFFE |
Lade Register mit einer Konstanten. |
| Register direct |
r0 = r1; |
LDW R0,R1 |
Lade Register mit dem Inhalt
eines anderen Registers. |
| Program direct |
func(); |
JSR func |
Unterprogrammaufruf zu einer
anderen Stelle im Programm ausführen. |
| Program relative |
goto near; |
BRA near |
Sprung zu einer nahe liegenden
anderen Stelle im Programm ausführen. |
| Program indirect |
(*a0)(); |
JSR (A0) |
Unterprogrammaufruf zu der durch
Register a0 bestimmten Stelle im Programm ausführen. |
| Data direct | r0 = variable; | LDW R0,variable |
Lade Register r0 mit dem Inhalt einer Speicherzelle. |
| Data indirect |
r0 = *a0; |
LDW R0,(A0) |
Lade Register r0 mit dem Inhalt der durch Register a0 bestimmten Speicherzelle. |
| Data predecrement indirect | r0 = *--a0; |
LDW R0,-(A0) |
Erniedrige Register a0 um die Grösse der Speicherzelle. Lade Register r0 mit dem Inhalt der durch a0 bestimmten Speicherzelle. |
| Data postincrement indirect | r0 = *a0++; |
LDW R0,(A0)+ |
Lade Register r0 mit dem Inhalt der durch Register a0 bestimmten Speicherzelle. Erhöhe a0 um die Grösse der Speicherzelle. |
| Data offset indirect | r0 = a0->offset; |
LDW R0,offset(A0) |
Lade Register r0 mit dem Inhalt
der durch Register a0 plus offset bestimmten Speicherzelle. Offset ist
eine Konstante. |
| Byte |
Type = 0 |
Type = 1 |
Type = 2 |
Type = 3,4 |
Type = 5 |
Type = 6 | Type =7 |
| #1 |
Opcode 1 |
Opcode 1 |
Opcode 1 | Opcode 1 |
Opcode 1 |
Opcode 1 | Opcode 1 |
| #2 |
Parameter 1a | Parameter 1a | Opcode 2 | Opcode 2 |
Opcode 2 | Opcode 2 |
|
| #3 |
Parameter 2a | Parameter 1b |
Parameter 1b | Parameter 1b |
|||
| #4 |
Parameter 2b |
Parameter 2b |
|||||
| #5 |
Parameter 3b |
||||||
| #6 |
Parameter 4b |
| rg1, rg2 |
ext |
|
| 0 |
R0, A0, D0, D4 |
full load/store |
| 1 |
R1, A1, D1, D5 |
half load/store no extend |
| 2 |
R2, A2, D2, immediate |
half load/store zero extend |
| 3 |
R3, A3, D3, data direct |
half load/store sign extend |
| sl1, sl2 |
|
| 0 |
R Register |
| 1 |
A Register |
| 2 |
D0..D3 Register |
| 3 |
D4, D5 oder Spezial |
| 4 |
data indirect |
| 5 |
data predecrement indirect |
| 6 |
data postincrement indirect |
| 7 |
data offset indirect |
| # |
L = 0 (R ALU) |
L = 1 (D ALU) |
| 0 |
no extend |
no extend |
| 1 |
zero extend |
zero extend |
| 2 |
sign extend |
sign extend |
| 3 |
+ |
+ |
| 4 |
- |
- |
| 5 |
NOT |
|
| 6 |
AND |
AND |
| 7 |
OR | |
| 8 |
XOR |
SL,1,Zero fill |
| 9 |
SL,8,Zero fill | |
| 10 |
LSR,1,Zero fill | |
| 11 |
LSR,8,Zero fill | |
| 12 |
ASR,1,Sign fill | |
| 13 |
ASR,8,Sign fill | |
| 14 |
RL |
|
| 15 |
RR |
| rg1 |
rg2 |
al1, al2 |
|
| 0 |
R0 oder D0 oder A0 oder D4 |
R0 oder D0 oder A0 oder D4 | R Register |
| 1 |
R1 oder D1 oder A1 oder D5 |
R1 oder D1 oder A1 oder D5 | D Register |
| 2 |
R2 oder D2 oder A2 oder 0 |
R2 oder D2 oder A2 oder 1 |
A Register |
| 3 |
R3 oder D3 oder A3 |
R3 oder D3 oder A3 oder 2 |
Mixed |
| CC |
Test |
if F = 0 |
if F = 1 |
| #0 |
1 |
JMP |
|
| #1 |
Z |
JNE |
JEQ |
| #2 |
C |
JGE |
JLT |
| #3 |
C | Z |
JGT |
JLE |
| #4 |
N ^ Z |
SJGE |
SJLT |
| #5 |
Z | (N ^ V) |
SJGT |
SJLE |
| Name |
State #2 |
State #2 |
| NOT reg |
execute ALU=NOT |
#2.0.5: reg ~= reg |
| SL reg,1 | execute ALU=SL,1,Zero fill | #2.0.8: reg <<= 1 |
| SL reg,8 | execute ALU=SL,8,Zero fill | #2.0.9: reg <<= 8 |
| LSR reg,1 | execute ALU=SR,1,Zero fill | #2.0.10: reg >>= 1 |
| LSR reg,8 | execute ALU=SR,8,Zero fill | #2.0.11: reg >>= 8 |
| ASR reg,1 |
execute ALU=SR,1,Sign fill |
#2.0.12: reg >>= 1 |
| ASR reg,8 | execute ALU=SR,8,Sign fill | #2.0.13: reg >>= 8 |
| RL reg |
execute ALU=RL | #2.0.14: C << reg <<
C |
| RR reg | execute ALU=RR | #2.0.15: C >> reg >> C |
| TST reg |
execute ALU=OR | #2.1.7: reg = 0 | reg |
| NEG reg | execute ALU=SUB | #2.1.4: reg = 0 - reg |
| ADD reg,1 | execute ALU=ADD | #2.2.3: reg += 1 |
| ADD reg,2 | execute ALU=ADD | #2.3.3: reg += 2 |
| SUB reg,1 | execute ALU=SUB | #2.4.3: reg += -1 |
| SUB reg,2 | execute ALU=SUB | #2.5.3: reg += -2 |
| AND reg1,reg2 |
execute ALU=AND | #2.6.6: reg1 &= reg2 |
| OR reg1,reg2 |
execute ALU=OR | #2.6.7: reg1 |= reg2 |
| XOR reg1,reg2 |
execute ALU=XOR | #2.6.8: reg1 ^= reg2 |
| ADD reg1,reg2 |
execute ALU=ADD | #2.6.3: reg1 += reg2 |
| SUB reg1,reg2 | execute ALU=SUB | #2.6.4: reg1 -= reg2 |
| CMP reg1,reg2 |
execute ALU=SUB | #2.7.4: N,Z,C,V = reg1 - reg2 |
| # |
Parameter |
| 0 |
Ein Register |
| 1 |
Konstante 0 und Register |
| 2 |
Register und Konstante 1 |
| 3 |
Register und Konstante 2 |
| 4 |
Register und Konstante -1 |
| 5 |
Register und Konstante -2 |
| 6 |
Zwei Register |
| 7 |
Zwei Register, Ergebnis verwerfen |
| # |
L = 0 (R ALU) |
L = 1 (D ALU) |
A ALU |
| 0 |
no extend |
no extend | no extend |
| 1 |
zero extend |
zero extend | |
| 2 |
sign extend |
sign extend |
sign extend |
| 3 |
+ |
+ |
+ |
| 4 |
- |
- |
|
| 5 |
NOT |
||
| 6 |
AND |
||
| 7 |
OR | ||
| 8 |
XOR |
SL,1,Zero fill | |
| 9 |
SL,8,Zero fill | ||
| 10 |
SR,1,Zero fill | ||
| 11 |
SR,8,Zero fill | ||
| 12 |
SR,1,Sign fill | ||
| 13 |
SR,8,Sign fill | ||
| 14 |
RL |
||
| 15 |
RR |
| Name |
State #2 |
State #3 |
State #4 |
State #5 |
| Jcc false Program direct | #2.8: Abus = PC; RD1, RD0 = DBus; PC += 2 | |||
| JMP, Jcc true Program direct | #2.8: Abus = PC; RD1, RD0 = DBus; PC += 2 | #3.0: PC = RD1, RD0 | ||
| JSR Program direct | #2.9: Abus = PC; RD1, RD0 =
DBus; PC += 2; A3 -= 2 |
#3.2: Abus = A3; Dbus = WD1, WD0 = PC | #4.0: PC = RD1, RD0 | |
| Jcc false Program relative | #2.10: Abus = PC; RD0 = DBus; PC += 1 | |||
| JMP, Jcc true Program relative | #2.10: Abus = PC; RD0 = DBus; PC += 1 | #3.1: JR = RD0,sign extend | #4.2: PC += JR |
|
| JSR Program relative | #2.11: Abus = PC; RD0 = DBus; PC += 1; A3 -= 2 | #3.2: Abus = A3; Dbus = WD1, WD0 = PC | #4.1: JR = RD0,sign extend | #5.2: PC += JR |
| Jcc false Program indirect | ||||
| JMP, Jcc true Program indirect | #2.11: PC = Ax mit x=0..3; | |||
| JSR Program indirect | #2.12: A3 -= 2 | #3.2: Abus = A3; Dbus = WD1, WD0 = PC | #4.3: PC = Ax mit x=0..3; | |
| RET | #2.13: Abus = A3; RD1, RD0 = Dbus; A3 += 2 | #3.0: PC = RD1, RD0 | ||
| Scc reg false |
#2.14: reg = 0; | |||
| Scc reg true |
#2.15: reg = NOT 0; |
| Name |
Klasse |
| LD reg,reg |
Transport |
| LD reg,mem |
|
| LD mem,reg |
| Instruction |
| Load Register, Register |
| Load Register, Immediate |
| Load Register, Data direct |
| Load Register, Data indirect |
| Load Register, Data predecrement indirect |
| Load Register, Data postincrement indirect |
| Load Register, Data offset indirect |
| Byte |
Bedeutung |
Bedeutung |
Bedeutung | Bedeutung | Bedeutung | |||
| #1 |
Opcode 1 |
Opcode 1 |
Opcode 1 | Opcode 1 |
Opcode 1 |
Opcode 1 | Opcode 1 |
Opcode 1 |
| #2 |
Parameter 1a |
Opcode 2 |
Parameter 1a |
Opcode 2 |
Opcode 2 | Parameter 1a |
Opcode 2 |
|
| #3 |
Parameter 2a |
Parameter 1b |
Parameter 1b | Parameter 2a |
Parameter 1b |
|||
| #4 |
Parameter 2b |
Parameter 3a |
Parameter 2b |
|||||
| #5 |
Parameter 4a |
Parameter 3b |
||||||
| #6 |
Parameter 4b |
| Abkürzung |
Name |
Bedeutung |
| N | Negative | Dieses Flag wird gesetzt wenn
das höchstwertige Bit des Ergebnisses gesetzt ist: N = c7 |
| Z |
Zero |
Dieses Flag wird gesetzt wenn
das Ergebnis der letzten Operation 0 ist: Z = ~(c7 | c6 | c5 | c4 | c3 | c2 | c1 | c0) |
| C |
Carry |
Dieses Flag wird gesetzt wenn
das Ergebnis einen Übertrag an der höchsten Stelle ergab: C = a7 & b7 | a7 & ~c7 | b7 & ~c7 |
| V |
Overflow |
Dieses Flag wird gesetzt wenn
das Ergebnis einen Übertrag an der zweithöchsten Stelle ergab: V = a7 & b7 & ~c7 | ~a7 & ~b7 & c7 |
| Rechnung dez |
Rechnung bin |
Ergebnis |
Z |
C |
N |
V |
Erklärung |
| 126 + 1 = 127 |
01111110 + 00000001 |
01111111 |
0 |
0 |
0 |
0 |
Erfolgreiche Addition von positiven signed Zahlen |
| -64 + -64 = -128 |
11000000 + 11000000 |
10000000 |
0 |
1 |
1 |
0 |
Erfolgreiche Addition von negativen signed Zahlen |
| 127 + 127 = -2 | 01111111 + 01111111 | 11111110 | 0 |
0 |
1 |
1 |
Überlauf bei Addition von positiven signed Zahlen |
| 127 - 64 = 63 |
01111111 - 01000000 |
00111111 |
0 |
0 |
0 |
0 |
Erfolgreiche signed Subtraktion
grössere Zahl minus kleinere Zahl |
| 64 - 127 = -63 |
01000000 - 01111111 |
11000001 |
0 |
0 |
1 |
1 |
Erfolgreiche signed Subtraktion kleinere Zahl minus grössere Zahl |
| 127 - 127 = 0 |
01111111 - 01111111 |
00000000 |
1 |
0 |
0 |
0 |
Erfolgreiche signed Subtraktion gleicher Zahlen |
| 0 - 127 = -127 |
00000000 - 01111111 |
10000001 |
0 |
1 |
1 |
1 |
Erfolgreiche Vorzeichenumkehr
einer positiven signed Zahl |
| 0 - -1 = 1 |
00000000 - 11111111 |
00000001 |
0 |
1 |
0 |
0 |
Erfolgreiche Vorzeichenumkehr einer negativen signed Zahl |
| 0 - -128 = -128 |
00000000 - 10000000 |
10000000 |
0 |
0 |
1 |
0 |
Überlauf bei
Vorzeichenumkehr einer negativen signed Zahl |
| 254 + 1 = 255 |
11111110 + 00000001 |
11111110 |
0 |
0 |
1 |
0 |
Erfolgreiche Addition zweier unsigned Zahlen |
| 255 + 255 = 254 |
11111111 + 11111111 |
11111110 |
0 |
1 |
1 |
0 |
Überlauf bei Addition von unsigned Zahlen |
| Programmiersprache C |
als Subtraktion |
Instruction |
Test unsigned |
Instruction |
Test signed |
| if (r0 > r1) |
if (r0-r1 > 0) |
JGT oder SGT |
C | Z == 0 |
SJGT oder SSGT |
Z | (N ^ V) == 0 |
| if (r0 >= r1) |
if (r0-r1 >= 0) | JGE, JCC oder SGE, SCC |
C == 0 |
SJGE oder SSGE |
N ^ V == 0 |
| if (r0 == r1) |
if (r0-r1 == 0) | JEQ oder SEQ |
Z == 1 |
||
| if (r0 != r1) |
if (r0-r1 != 0) |
JNE oder SNE |
Z == 0 |
||
| if (r0 <= r1) |
if (r0-r1 <= 0) | JLE oder SLE |
C | Z == 1 |
SJLE oder SSLE |
Z | (N ^ V) == 1 |
| if (r0 < r1) |
if (r0-r1 < 0) | JLT, JCS oder SLT, SCS |
C == 1 |
SJLT oder SSLT |
N ^ V == 1 |
| Cin |
a |
b |
Cout |
f |
| 0 |
0 |
0 |
0 |
0 |
| 0 |
0 |
1 |
0 |
1 |
| 0 |
1 |
0 |
0 |
1 |
| 0 |
1 |
1 |
1 |
0 |
| 1 |
0 |
0 |
0 |
1 |
| 1 |
0 |
1 |
1 |
0 |
| 1 |
1 |
0 |
1 |
0 |
| 1 |
1 |
1 |
1 |
1 |